RAG Search with AWS Lambda and Bedrock
How to create fast and cost-effective RAG search using AWS Lambda and Bedrock
Arti

Today I would like to show you how I solved with Retrieval-Augmented Generation (RAG) Search my problem of poor Large Language Model (LLM) response results.
I was creating a system, one of the elements of which was the cooperation of the LLM model with the Google search engine. The model specified what queries it wanted to perform under a given case, and the search engine provided it with the text of the retrieved pages.
The resulting data, however, was not always ideal. The page could be very large, and the interesting information was only a fraction of the entire page content.
This caused problems:
- large attached files caused a significant increase in waiting for a response from the model,
- larger input increased the cost of the query,
- large text not always related to the topic caused hallucinations of the model.
After a brief research, I decided to use the RAG search method. However, I could not use the classic vector database approach because my data was not on my server. In addition, I cared about speed; my solution is serverless, so I didn’t want to lose the speed I had for the time being.
The choice was to create AWS Lambda, using AWS Bedrock model Titan for embedding and Numpy libraries for calculations.
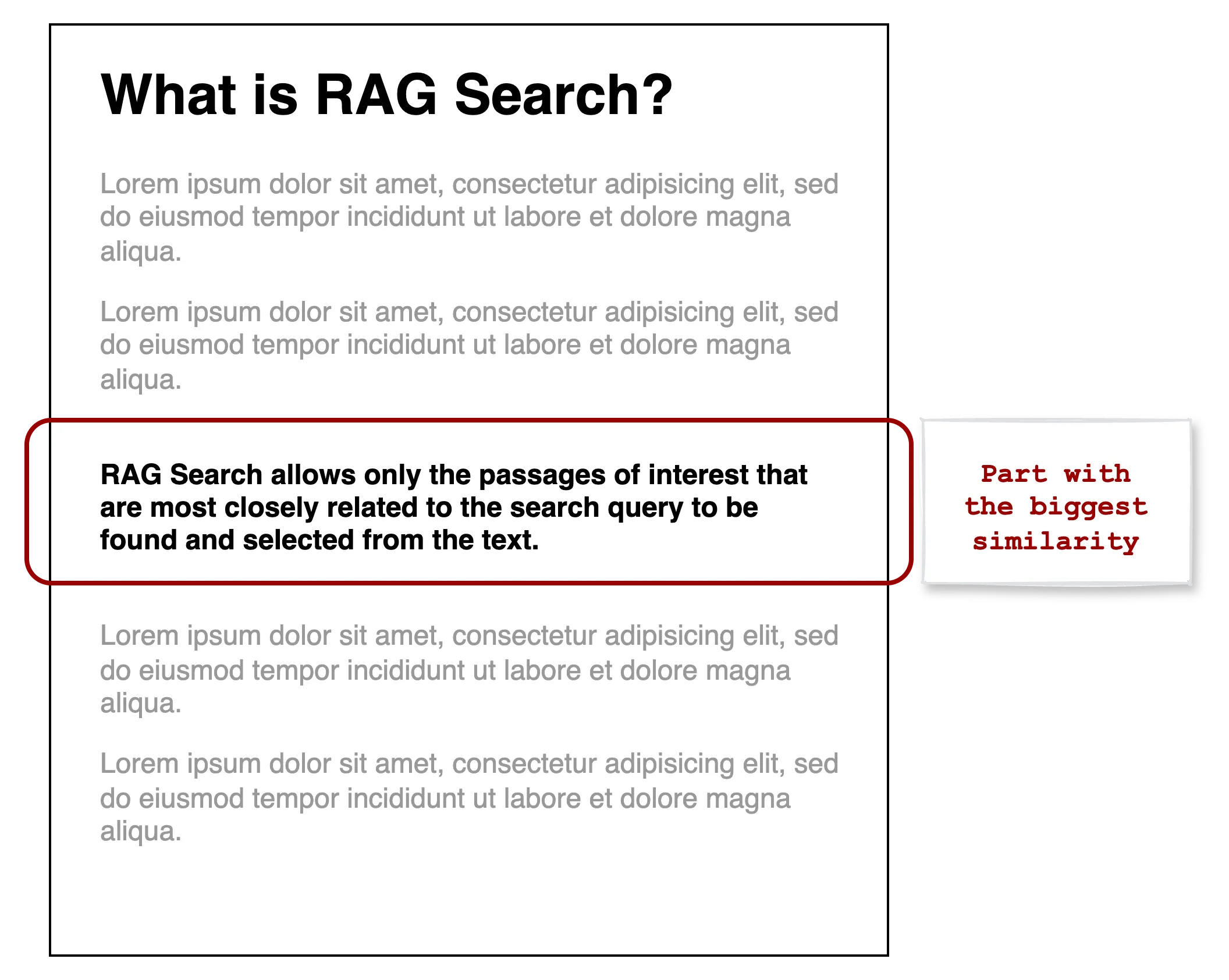
What is RAG Search?
RAG Search is a method for finding interesting passages in a text using computation on vectors. In the simplest terms, it is a search for the answer to a question in an article that contains a lot of unnecessary information.
Below, you can find an example of what RAG looks like in practice together with its definition.
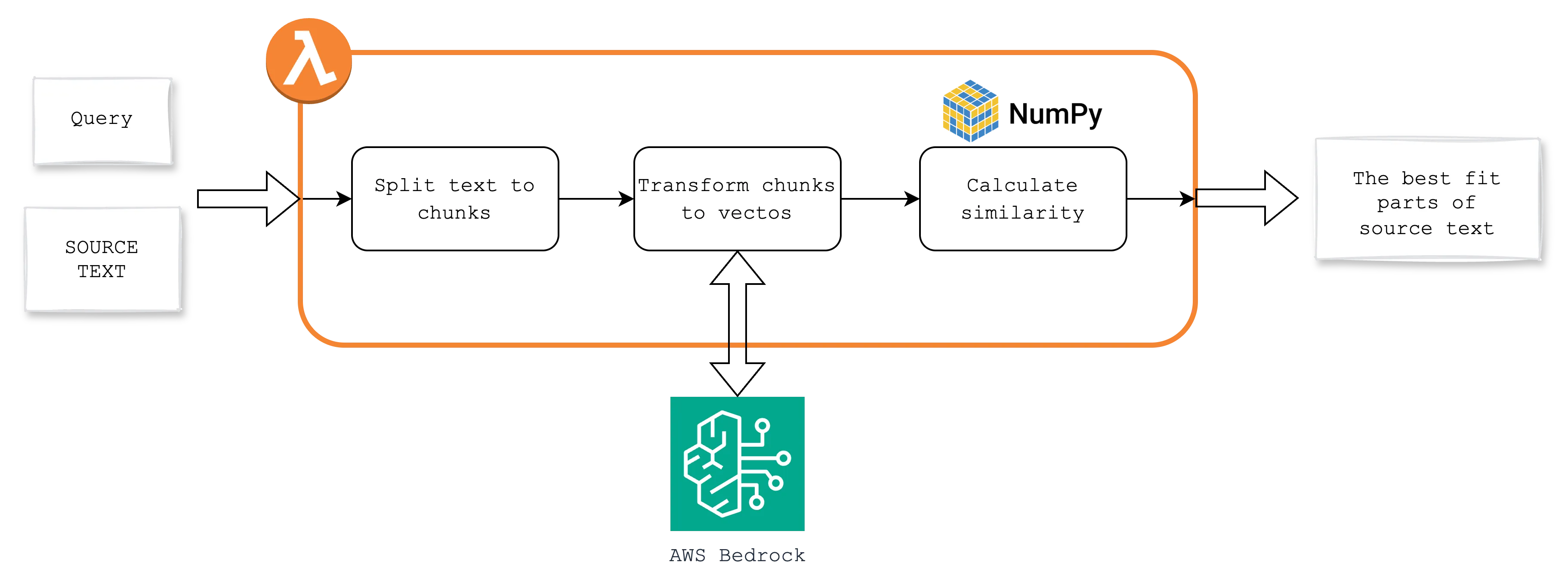
Implementation
The principle of the search is generally very simple and is contained in 3 steps:
- divide the text into parts, here called chunks,
- determine for each part a vector,
- compare the query vector with the vectors of chunks and select, for example, the best 3.
I decided to split the text after the characters. I borrowed the function from the article Medium
def split_full_text(text, chunk_size=500, overlap=50):
text = text.replace("\n", " ")
chunks = []
start = 0
while start < len(text):
end = min(start + chunk_size, len(text))
chunk = text[start:end]
chunks.append({"text": chunk})
start += chunk_size - overlap
return chunksHaving already had text fragments, it was now necessary to change them into vectors. Since the solution is on AWS the choice was AWS Bedrock.
MODEL_ID = "amazon.titan-embed-text-v2:0"
bedrock_client = boto3.client("bedrock-runtime")
def transform_text_to_vector(text: str):
request = json.dumps({"inputText": text})
response = bedrock_client.invoke_model(modelId=MODEL_ID, body=request)
model_response = json.loads(response["body"].read())
embedding = model_response["embedding"]
input_text_token_count = model_response["inputTextTokenCount"]
print(f"Input token counts: {input_text_token_count}")
return embeddingAll that’s left is a function comparing 2 vectors, but for that we’ll need Numpy. It is best to add it to the Layer that we will attach to our Lambda. The following command will create the file you need to upload like a Layer.
mkdir python
pip install numpy -t python --platform manylinux2014_x86_64 --implementation cp --python-version 3.11 --upgrade --only-binary=:all:
zip layer.zip -r pythonWe will use the cosine similarity for comparison. I borrowed the function from the article Building a tiny vector store from scratch
def cosine_similarity(store_embeddings, query_embedding, top_k):
dot_product = np.dot(store_embeddings, query_embedding)
magnitude_a = np.linalg.norm(store_embeddings, axis=1)
magnitude_b = np.linalg.norm(query_embedding)
similarity = dot_product / (magnitude_a * magnitude_b)
sim = np.argsort(similarity)
top_k_indices = sim[::-1][:top_k]
return top_k_indicesFinally, we can put everything together and prepare our Lambda. It takes 2 input parameters:
- query — the query we are looking for
- content — the source page
import json
import boto3
import numpy as np
TOP_K = 3
def lambda_handler(event, context):
content = event["content"]
query = event["query"]
content_chunks = split_full_text(content)
query_vector = transform_text_to_vector(query)
content_vectors = []
for chunk in content_chunks:
content_vector = transform_text_to_vector(chunk["text"])
content_vectors.append(content_vector)
print(f"Content vector: {len(content_vectors)}")
top_k_indices = cosine_similarity(content_vectors, query_vector, TOP_K)
result = []
for top_k_index in top_k_indices:
print(content_chunks[top_k_index])
result.append(content_chunks[top_k_index]["text"])
return resultThe result is a list with the TOP_K most matched fragments to the query.
Summary
My solution is very quick and simple. It uses simple components that fit easily into AWS Lambda. The use of serverless allows unlimited scaling of the solution, the Numpy library computes vectors in an instant, and Bedrock works great as an embedded.
Search has significantly speed up my model, improved the quality of responses and reduced costs. The difference in execution time is visible to the naked eye. Throwing an entire page into the model often resulted in a timeout despite setting it for 5 minutes. Currently, it rarely exceeds 10 seconds.
I hope you will find them useful as well.